
目录
借助 Web UI,我们可以更好地理解 InfluxDB 的功能划分,接下来,我们就从 Web UI入手,先了解InfluxDB 的基本功能。
数据源相关
Load Data(加载数据)
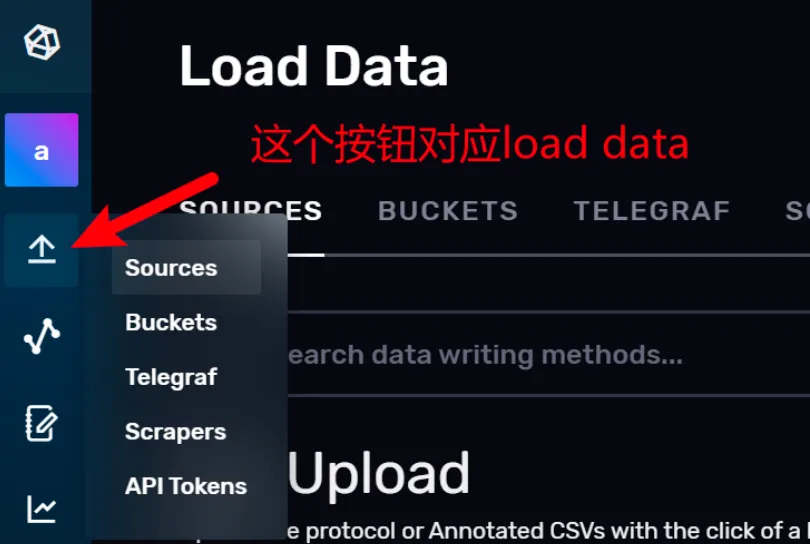
如图所示,页面上左侧的向上箭头,对应着 InfluxDB Web UI 的 Load Data(加载数据) 页面。
1)上传数据文件
在 Web UI 上,你可以用文件的方式上传数据,前提是文件中的数据符合 InfluxDB 支持的类型,包括CSV、带Flux 注释的 CSV 和 InfluxDB 行协议。

点击其中任意一个按钮,将进入数据的上传页面,页面中包含了详细的说明文档,包含你的数据应该符合什么格式,你要把数据放到哪个存储桶里,还包括用命令行来上传数据的命令模板。

2)写入 InfluxDB 的代码模板
InfluxDB 提供了各种编程语言的连接库,你甚至可以在前端嵌入向 InfluxDB 写入数据的代码,因为InfluxDB 向外提供了一套功能完整的REST API。

点击任何一个语言的 LOGO,你会看到使用这门语言,将数据写入到 InfluxDB 的代码模板。
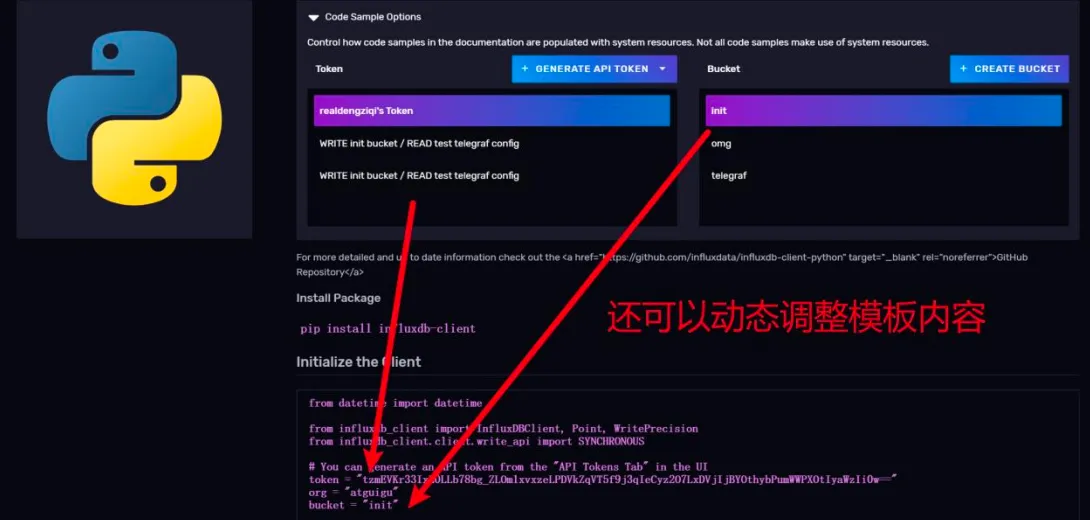
建议从这里拷贝初始化客户端的代码。
配置Telegraf 的输入插件:

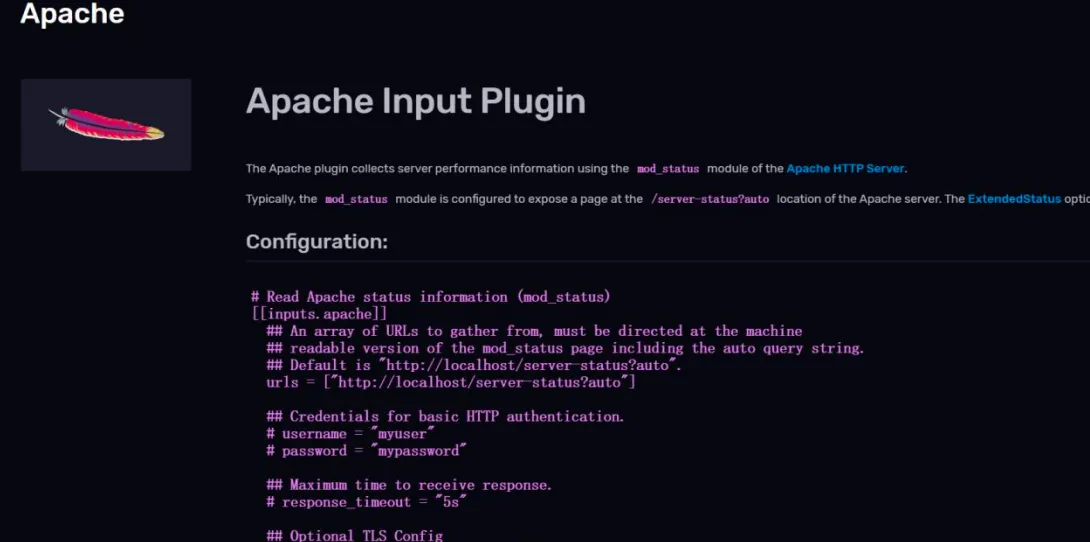
Telegraf 是一个插件化的数据采集组件,在这里你可以找一下没有对应你的目标数据源的插件,点击它的 logo。可以看到这个插件配置的写法,但是关于这方面的内容,还是建议参考 Telegraf 的官方文档,那个更细更全一些。
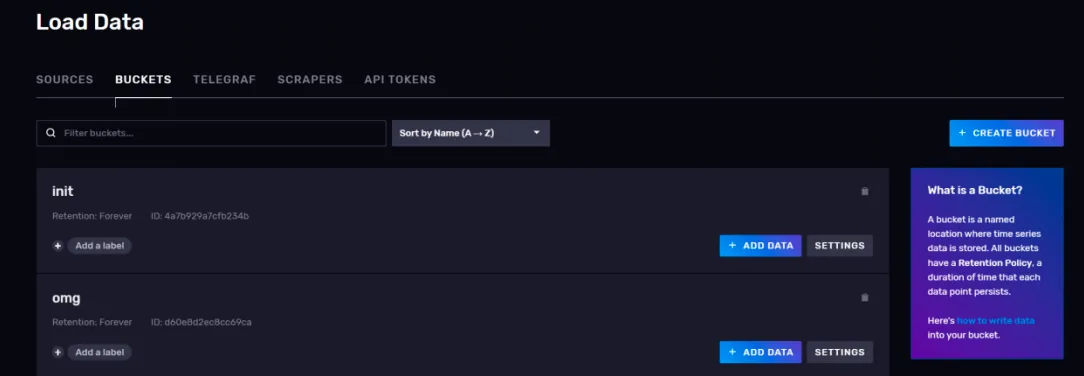
管理存储桶
你可以将 InfluxDB 中的 bucket 理解为普通关系型数据库中的 database。在 Load data 页面上,点击上访的BUCKETS 选项卡,就可以进入bucket 管理页面了
提示
InfluxDB 是一个无模式的数据库,也就是除了在输入数据之前需要显示创建存储桶(数据库),你不需要手动创建 measurement 或者指定各个 field 都是什么类型,你甚至可以前后在同一个measurement 下插入 filed 不同的数据。
1)创建 Bucket
点击右上角的 CREATE BUCKET 按钮,会有一个创建存储桶的弹窗,这里你可以给bucket 指定一个名称和数据的过期时间。比如,你设置过期时间为 6 小时,那 InfluxDB 就会自动把这个存储桶中距离当前时间超过 6 小时的数据删除。
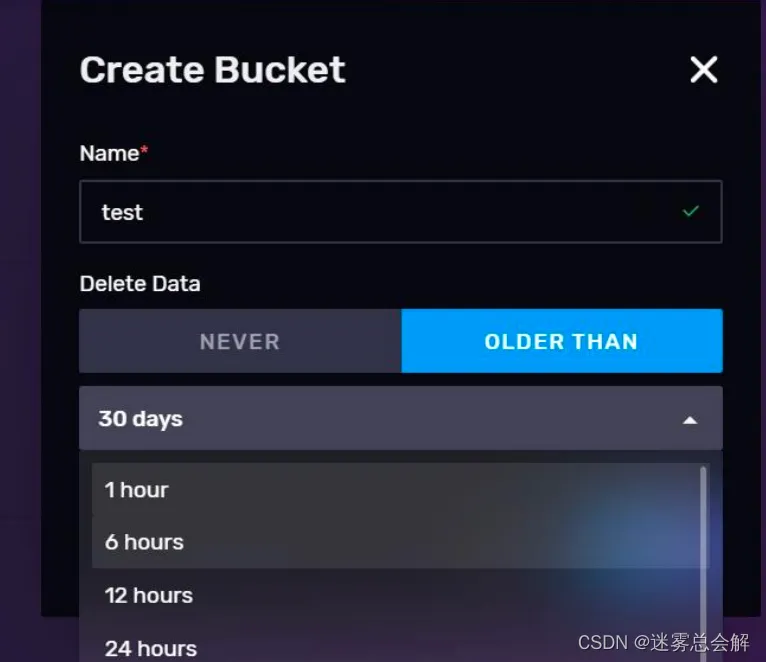
2)调整 Bucket 的设置
存储桶的过期时间的名称都是可以修改的,点击任一 Bucket 信息卡的 SETTINGS 按钮会弹出一个调整设置的会话框。
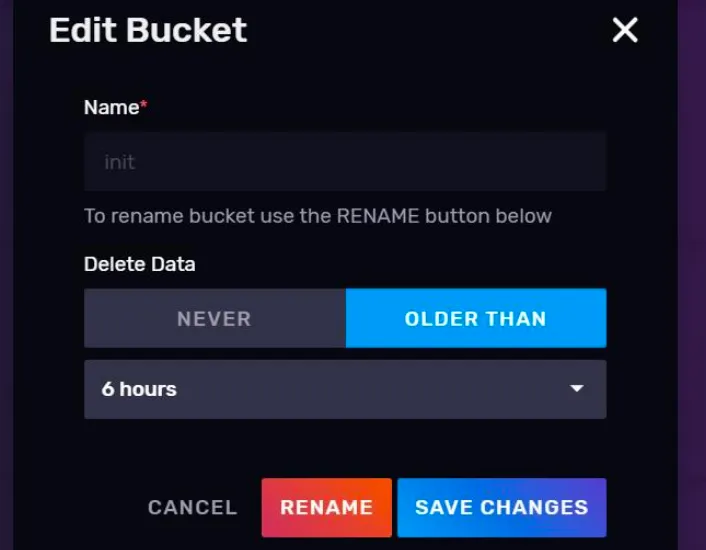
重命名是 InfluxDB 不建议的操作,因为大量的代码和 InfluxDB 定时任务都需要通过指定 Bucket 的名称来进行连接,贸然更改 Bucket 的名称可能导致这些程序无法正常工作。
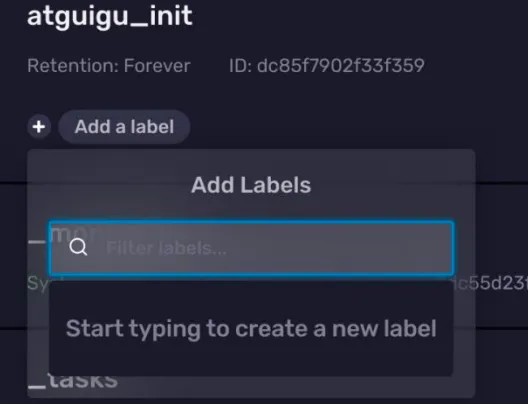
3)设置 Label
在每个 Bucket 信息卡的左下方都有一个 Add a label 按钮,点击这个按钮,你可以为Bucket 添加一个标签。不过这个功能一般很少用
4)向 Bucket 添加数据
每个存储桶信息卡的右边都有一个添加数据按钮,点击这个按钮可以快速导入一些数据。这里还可以创建一个抓取任务(被抓取的数据在格式上必须符合 prometheus 数据格式)
示例:创建 Bucket 并从文件导入数据
1)创建 Bucket
将鼠标悬停在☝️ 左侧的按钮上,点击 Buckets,进入 Bucketde 的管理页面。

点击 CREATE BUCKET 按钮,指定一个名称,这里我们将其设为 example01, 删除策略保留默认的NEVER,表示永远不会删除数据
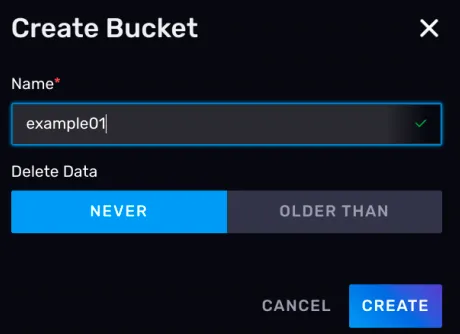
点击CREATE 按钮,可以看到我们的Buckets 已经创建成功了。
2)进入上传数据引导页面
在 Load Data 页面,点击 Line Prtocol 进入 InfluxDB 行协议格式数据的上传引导页面。

3)录入数据

- 点击选择存储桶
- 选择ENTER MANUALLY,手动输入数据
- 将数据粘到输入框
- 在右侧指明时间精度,包括纳秒、微秒、毫秒和秒
数据如下:
textpeople,name=tony age=12 people,name=xiaohong age=13 people,name=xiaobai age=14 people,name=xiaohei age=15 people,name=xiaohua age=12
当前我们写的数据格式叫做 InfluxDB 行协议。最后点击 WRITE DATA,将数据写到 InfluxDB。如果出现 Data Written Successfully, 那么说明数据写入成功。
管理 Telegraf 数据源
点击 Load Data 页面的 TELEGRAF 选项卡,可以快速生成一些 Telegraf 配置文件。并向外暴露一个端口,允许 telegraf 远程使用 InfluxDB 中生成的配置。
1)什么是 Telegraf
Telegraf 是 InfluxDB 生态中的一个数据采集组件,它可以讲各种时序数据自动采集到InfluxDB。现在,Telegraf 不仅仅是 InfluxDB 的数据采集组件了,很多时序数据库都支持与 Telegraf 进行协作,不少类似的时序数据收集组件选择在 Telegraf 的基础上二次开发。
2)创建 Telegraf 配置文件
InfluxDB 的 Web UI 为我们提供了几种最常用的 telegraf 配置模板,包括监控主机指标、云原生容器状态指标,nginx 和 redis 等。
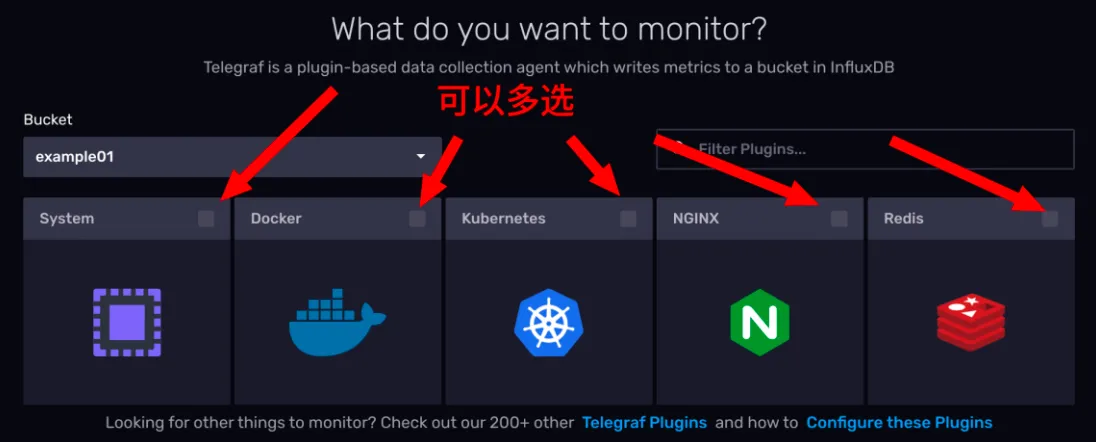
通过页面,你可以勾选几种监控目标,然后一步步操作去创建一个 Telegraf 的配置文出来。
3)管理 Telegraf 配置文件接口
完成Telegraf 的配置后,页面上会多出一个关于 telegraf 实例的信息卡。如图所示:

点击蓝色的 Setup Instructions。
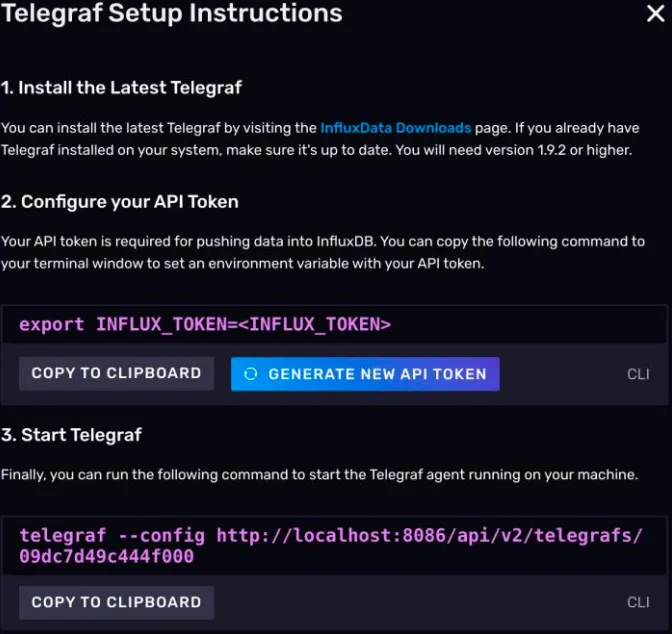
会弹出一个对话框,引导你完成 telegraf 的配置。可以看到第三步的命令。
shtelegraf --config http://localhost:8086/api/v2/telegrafs/09dc7d49c444f000
这个命令中有一个 URL,其实意思也就是 InluxDB 向外提供了一个 API,通过这个API 你可以访问到刚才生成的配置文件。
4)修改 Telegraf 配置
已经生成的配置文件如何去修改呢?你可以点击卡片的标题。

这个时候,会弹出一个配置文件的编辑页面,不过这个时候没有交互式的选项了,你需要自己直接面对配置文件。
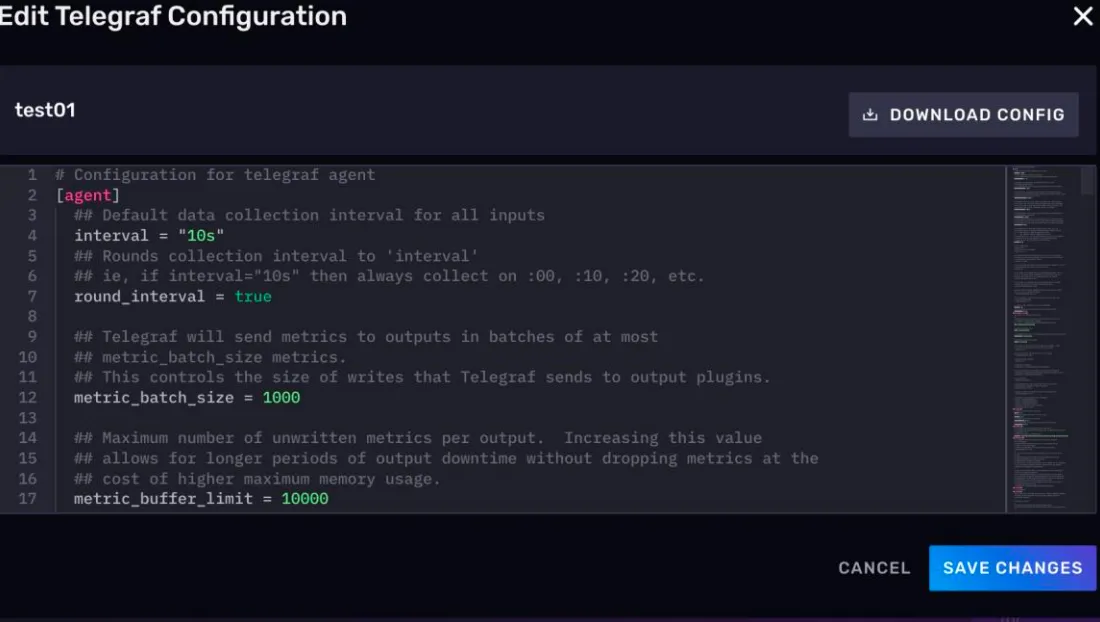
修改完配置文件后,记得点击右方的 SAVE CHANGES 保存修改。
示例:使用 Telegraf 将数据收集到 InfluxDB
在本示例中,我们会使用 Telegraf 这个工具将一台机器上的 CPU 使用情况转变成时序数据,写到我们的InfluxDB 中。
1)下载 Telegraf
可以使用下面的命令下载 telegraf:
shwget https://dl.influxdata.com/telegraf/releases/telegraf-1.23.4_linux_amd64.tar.gz
2)解压压缩包
将 telegraf 解压到目标路径。
shtar -zxvf telegraf-1.23.4_linux_amd64.tar.gz -C /opt/module/
3)创建一个新的 Bucket
创建一个名为 example02 的 buckets,因为是演示,所以可以将过期时间设为 1 小时。设置好后点击CREATE。
4)在 Web UI 上创建 telegraf 配置文件
-
在左侧的工具栏上点击Telegraf 按钮。
-
点击右侧蓝色的 CREATE CONFIGURATION 创建 telegraf 配置文件
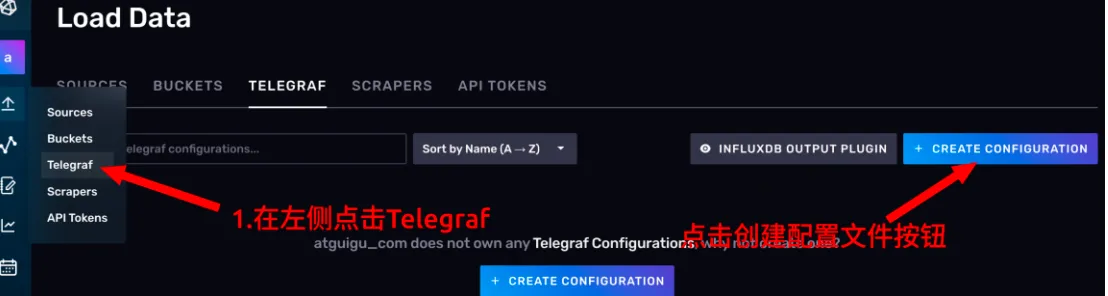
- 在 Bucket 栏选择 example02,表示让 telegraf 将抓取到的数据写到 example02 存储桶中,下面的选项卡勾选 System。点击 CONTINUE。
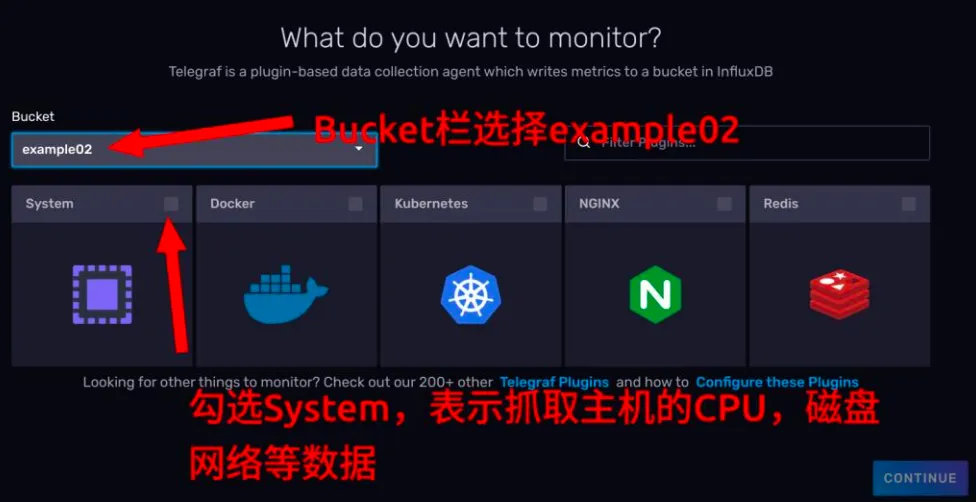
- 点击 CONTINUE 按钮后,会进入一个配置插件的页面。你可以自己决定是否启用这些插件。这里需要给生成的 Telegraf 配置起一个名字,方便管理。
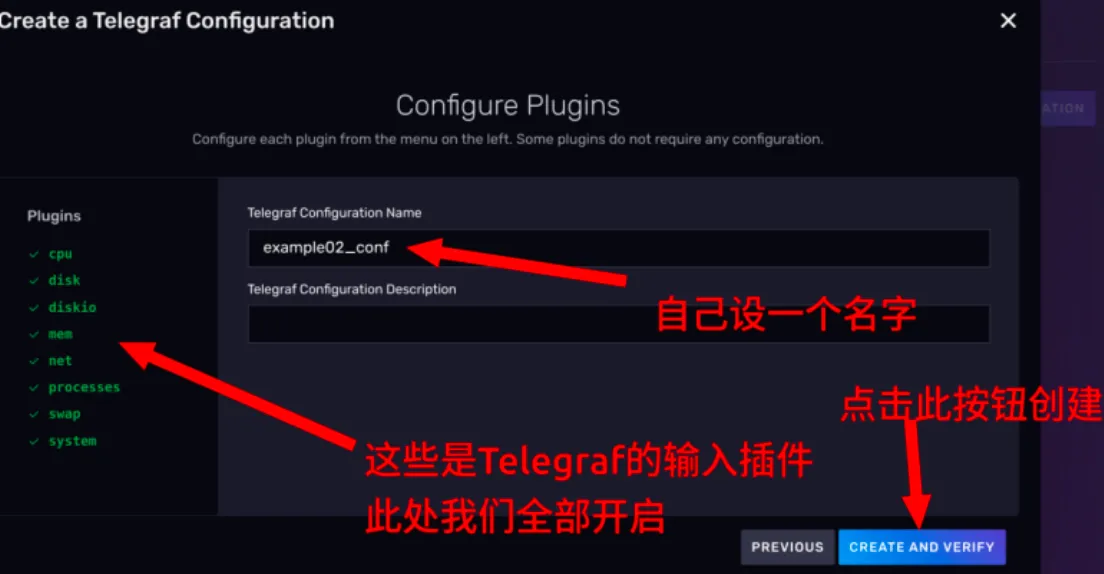
- 点击 CREATE AND VERIFY 按钮,这个时候其实 Telegraf 的配置就已经创建好了,你会进入一个Telegraf 的配置引导界面,如图所示:
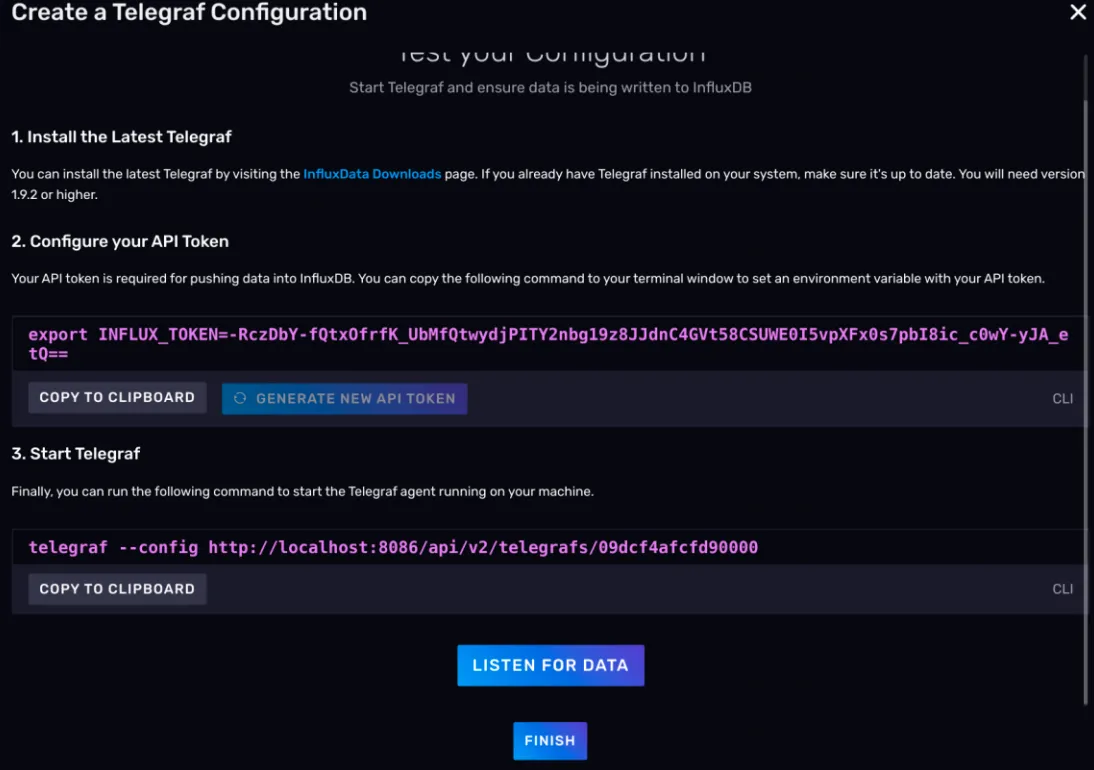
5)声明 Telegraf 环境变量
按照 Web UI 上的建议,首先,你要在部署 Telegraf 的主机上声明一个环境变量叫INFLUX_TOKEN,它是用来赋予 Telegraf 向 InfluxDB 写数据权限的。这里我们就不配环境变量了,请在单一的shell 会话下完成后面的操作。
所以到你下载好 Telegraf 的机器上,执行下面的命令。(注意!TOKEN 是随机生成的, 请按照自己的情况修改命令)
shexport INFLUX_TOKEN=v4TsUzZWtqgot18kt_adS1r-7PTsMIQkbnhEQ7oqLCP2TQ5Q-PcUP6RMyTHLy4IryP1_2rIamNarsNqDc_S_eA==
6)启动 Telegraf
首先 cd 到我们解压的 telegraf 目录。
shcd /opt/module/telegraf-1.23.4
telegraf 的可执行文件在 ./usr/bin 目录下。cd 过去。
sh cd ./usr/bin
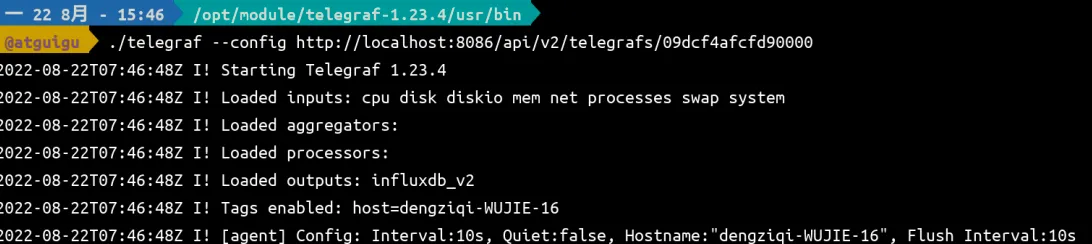
从 Web UI 中复制运行 telegraf 的命令,修改 host 然后执行,我的telegraf 和InfluxDB 在同一台机器上,所以可以使用 localhost。最终命令如下。
运行效果如下图所示。
7)验证数据采集结果
- 点击左侧按钮进入Data Explorer 页面。
- 在左下角第一个选项卡选择 example02,表示要从 example02 这个存储桶中查数据。
- 点击好第一个选项卡后,会自动弹出第二个选项卡,勾选 cpu。
- 点击右上方的 SUBMIT 按钮。
- 如果出现折线图,说明我们成功地使用Telegraf 把数据导进来了。

8)编写启停脚本
后面我们很多时候都要使用 telegraf 抓取的主机监控数据来进行查询演示。为了方便启停,我们编写一个shell 脚本来管理 telegraf 任务。
- 首先 cd 到~/bin 路径下,如果
路径下没有 bin,就创建 bin 这个目录。通常,/bin 是 PATH 环境变量包含的一个目录。
shcd ~
mkdir bin
cd ~/bin
- 到~/bin 路径下创建一个文件 host_tel.sh
shvim host_tel.sh
- 键入如下内容
sh#!/bin/bash
is_exist(){
pid=`ps -ef | grep telegraf | grep -v grep | awk '{print $2}'`
# 如果不存在返回 1,存在返回 0
if [ -z "${pid}" ]; then
return 1
else
return 0
fi
}
stop(){
is_exist
if [ $? -eq "0" ]; then
kill ${pid}
if [ $? -eq "0" ]; then
echo "进程号:${pid},弄死你"
else
echo "进程号:${pid},没弄死"
fi
else
echo "本来没有 telegraf 进程"
fi
}
start(){
is_exist
if [ $? -eq "0" ]; then
echo "跑着呢,pid 是${pid}"
else
export INFLUX_TOKEN=v4TsUzZWtqgot18kt_adS1r-7PTsMIQkbnhEQ7oqLCP2TQ5Q-PcUP6RMyTHLy4IryP1_2rIamNarsNqDc_S_eA==
/opt/module/telegraf-1.23.4/usr/bin/telegraf --config http://localhost:8086/api/v2/telegrafs/09dcf4afcfd90000
fi
}
status(){
is_exist
if [ $? -eq "0" ]; then
echo "telegraf 跑着呢"
else
echo "telegraf 没有跑"
fi
}
usage(){
echo "哦!请你 start 或 stop 或 status"
exit 1
}
case "$1" in
"start")
start
;;
"stop")
stop
;;
"status")
status
;;
*)
usage
;;
esac 最后
- 最后给这个脚本加上一个执行权限,你可以执行下面的代码。
shchmod 755 ./host_tel.sh
管理抓取任务
1)什么是抓取任务
抓取任务就是你给定一个 URL,InfluxDB 每隔一段时间去访问这个链接,把访问到的数据入库。
在 InfluxDB 1.x 的时候,类似的任务只能由Telegraf 来实现。在 InfluxDB 2.x 中,内置了抓取功能(但是定制性上不如 Telegraf,比如轮询间隔只能是 10 秒)
另外, 目标 URL 暴露出来的数据格式必须得是 Prometheus 数据格式。
2)InfluxDB 自身暴露的监控接口
你可以访问 http://localhost:8086/metrics 来查看 InfluxDB 暴露出来的性能数据。这里面有,InfluxDB 的 GC 情况
示例:让 InfluxDB 主动拉取数据
1)创建一个存储桶
创建了一个名为 example03 的存储桶。数据的过期时间设为 1 小时。
2)创建抓取任务
-
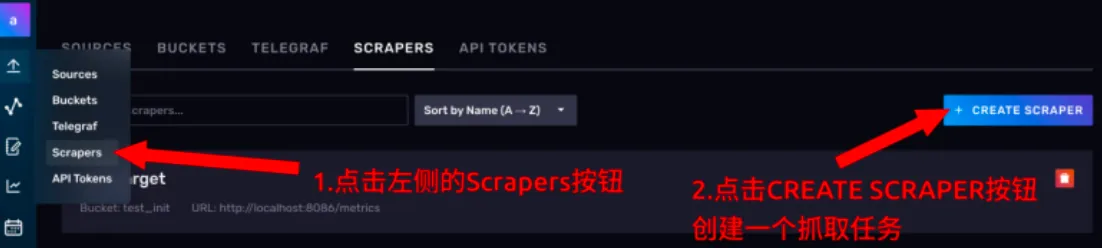
进入抓取任务的管理页面
-
点击CREATE SCRAPER 按钮,创建抓取任务。
-
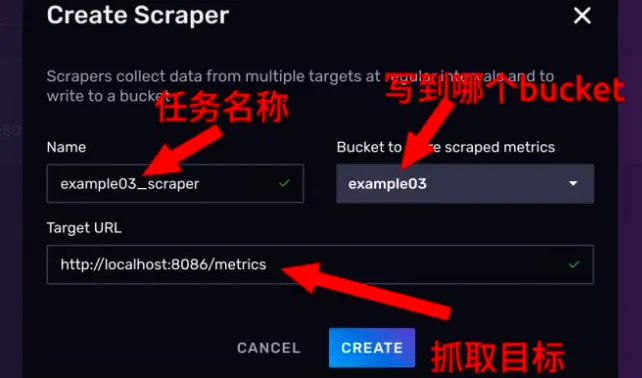
在对话框上,给抓取任务起一个名字,此处命名为 example03_scraper
-
右方的下拉框上,选择我们刚才创建的存储桶,example03。
-
最下方设置一下目标路径,最后点击 CREATE
- 如果页面上出现新的卡片,说明配置成功。接下来去看一下数据有没有进来。

3)验证抓取结果
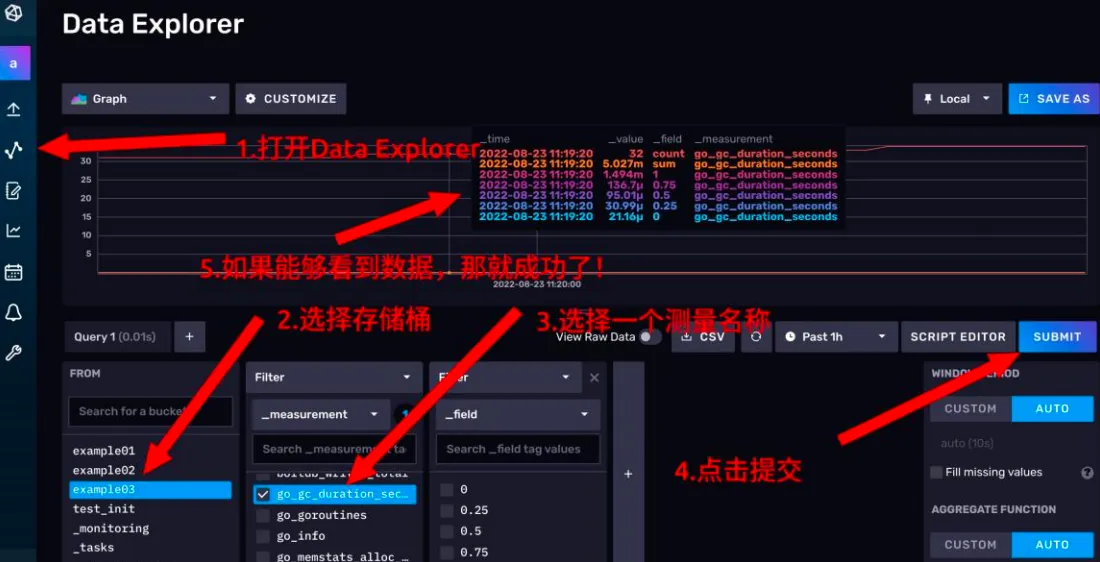
- 点击左侧的按钮,打开Data Explorer
- 在左下角第一个卡片选择要从哪个存储桶抽取数据,本例对应的是 example03
- 第一个卡片选择好后,会自动弹出第二个卡片,你可以选择任意一个指标名称。
- 点击右侧的 SUBMIT 按钮,提交查询。
- 如果折线图成功加载,说明有数据了,抓取成功!
管理 API Token
点击左侧的 API Tokens 按钮,进入 API Token 的管理页面。

1)API Token 是干什么用的
简单来说,influxdb 会向外暴露一套 HTTP API。我们后面要学的命令行工具什么的, 其实都是封装的对 influxdb 的 http 请求。所以,在 InfluxDB 中,对权限的管理主要就体现在 API 的 Tokens 上。客户端会将 token 放到 http 的请
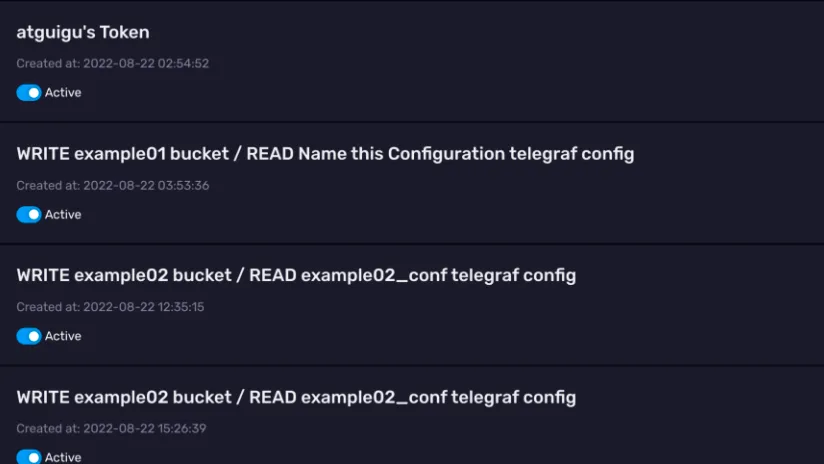
2)查看 API Token 权限
截至目前,我们还没有自己手动创建过 API Token。但是可以看到页面上已经有一些Token 了,这些 Token 是由我们之前示例里面的操作自动生成的。
3)了解 tony’s Token
现在,我们围绕着 InfluxDB 中已有的 Token 来学习相关的知识,我们的 InfluxDB 上现在只有初始化时创建的tony 账户,在 Token 列表中,我们可以看到有一个名为tony’s Token 的 token。
1.修改 token 的名称
点击 token 右边的符号,可以修改token 名称。
-
没有客户端会用 token 的名称来调用 token,所以修改 token 名称不会影响已经部署的应用。
-
InfluxDB 从未要求 token 的名称必须全局唯一,所以名称重复也是可以的。
2.token 可以临时关停、也可以删除
正如你说看到,token 卡片下面的 Active 按钮是一个开关,可以在启用和停用之间进行切换。同时,你也可以删除 token,但是这可能对你已经部署的应用产生不可挽回的影响。
3.查看 Token 权限
点击 token 的名称,可以看到这个 token 具体有哪些权限。这里我们比较两个token,可以看到 tony’ Token 的权限很高。
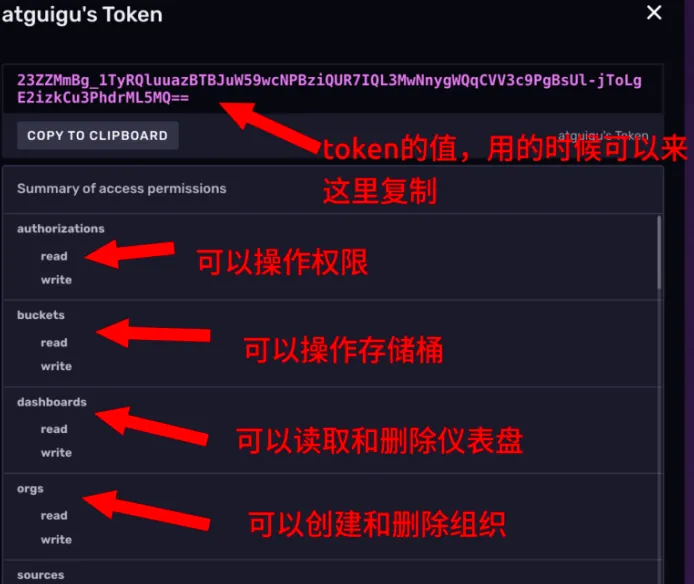
下面这个Token 是我们前面示例,生成 Telegraf 配置的时候自动生成的 token。

点开看一下它的权限。
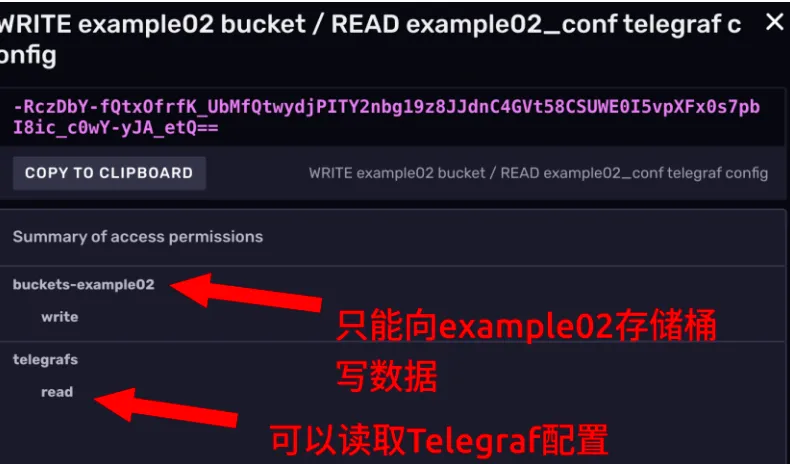
可以看到这个 token 的权限就小得多了,它只能向一个存储桶里写数据,查的权限都没有呢。
4)创建 API Token
页面的右方有一个 GENERATE API TOKEN。点一下会出来一个下拉菜单,这其实是Web UI 上的权限模板

在 Web UI 上,有两种类型的模板让你可以快速创建 token。
- Read/Write API Token 仅读写存储桶的Token。创建Token 时还可以限定这个Token 能操作哪些存储桶。

- All Access API Token 生成带所有权限的Token
注意!InfluxDB 的 Token 是可以进行更细的管理的,Web UI 上给的只是生成 Token 的模板,准备了用户的常用需求,但不代表它的全部功能。
查询工具
关于 InfluxDB 的查询,需要用户掌握一门叫 FLUX 的语言。本节暂时不讲解 FLUX 语言的知识,而是先了解InfluxDB 重要的两个开发工具——Data Explorer 和Notebook。
Data Explorer
explorer,探险家、探索者的意思。所以正如其字面意思,你可以使用Data Explorer 探索数据,理解数据。说白了,就是你可以尝试性地写写 FLUX 查询语言(InfluxDB 独创的一门独立查询语言),看一下数据的效果。开发过程中,你可以将它作为一个 FLUX 语言的 IDE。
点击左边的图标,进入Data Explorer。我们可以将 Data Explorer 的界面简单分为两个区域,上半部分为数据预览区,下半部分为查询编辑区。
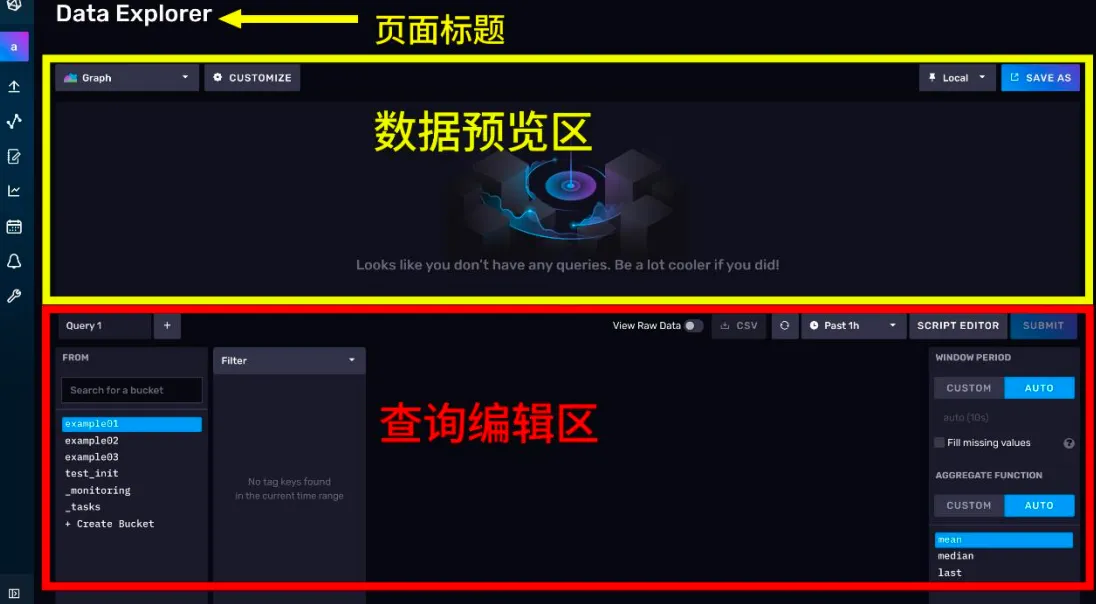
1)查询编辑区
查询编辑区为你提供了两种查询工具,一个是查询构造器,一个是 FLUX 脚本编辑器。
- 查询构造器
你一进入 Data Explorer 页面,默认会打开查询构造器。使用查询构造器,你可以通过点按的方式完成查询。它背后的原理其实是根据你的设置,自动生成一条 FLUX 语句,提交给数据库完成查询。
能够出现查询构造器这种东西,说明时序数据的查询之间遵循着某种规律。不同业务之间的查询步骤可能高度相似

如上图,这是查询构造器的极简介绍。
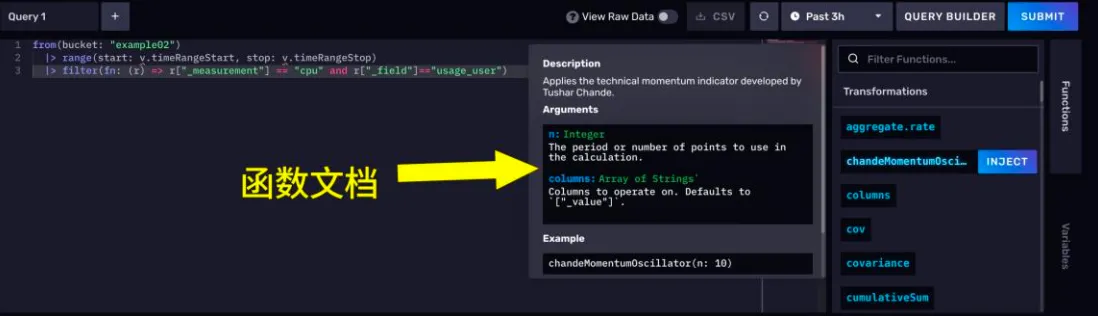
- FLUX 脚本编辑器
你可以手动将查询构造器切换为 FLUX 脚本编辑器。然后愉快地编写 FLUX 脚本,实现各种奇葩查询。编辑器十分友好,还带自动提示和函数文档。
2)数据预览区
数据预览区可以将你的数据展示出来。下图是一个效果图。
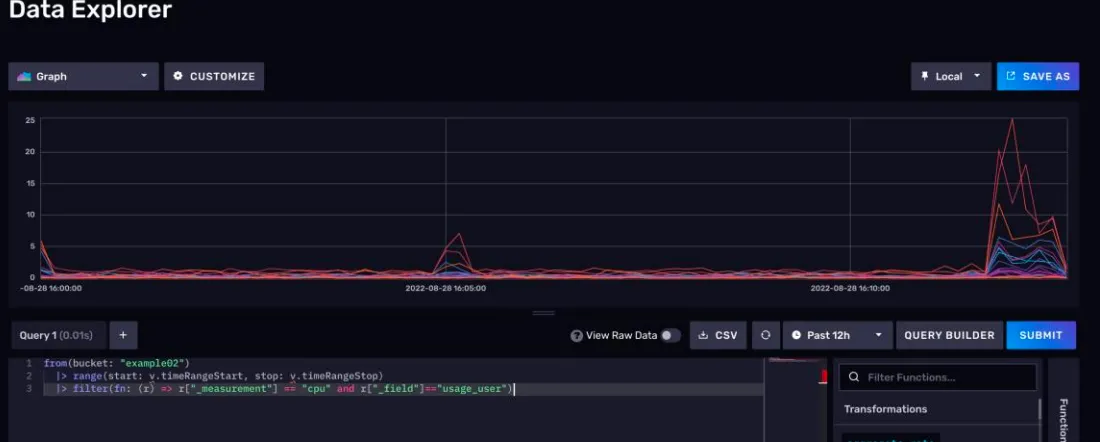
默认情况下,数据预览区会将你的数据展示为一个折线图。不过除此之外,你还可以让数据展示为散点图、饼图或者查看原始数据等等。
3)其他功能
除了查询和展示数据的功能外。Data Explorer 还有一些拓展功能
- 将数据导出为 CSV
在执行查询之后,DataExplorer 允许你快速地将数据导出为一个 CSV 文件。
- 将当前查询和可视化效果保存为仪表盘的一个单元
你可以将当前的查询逻辑和图形展示保存为某个仪表盘的一部分。这个功能需要在查询逻辑已经实现的前提下,点击右上角的 SAVE AS 触达。
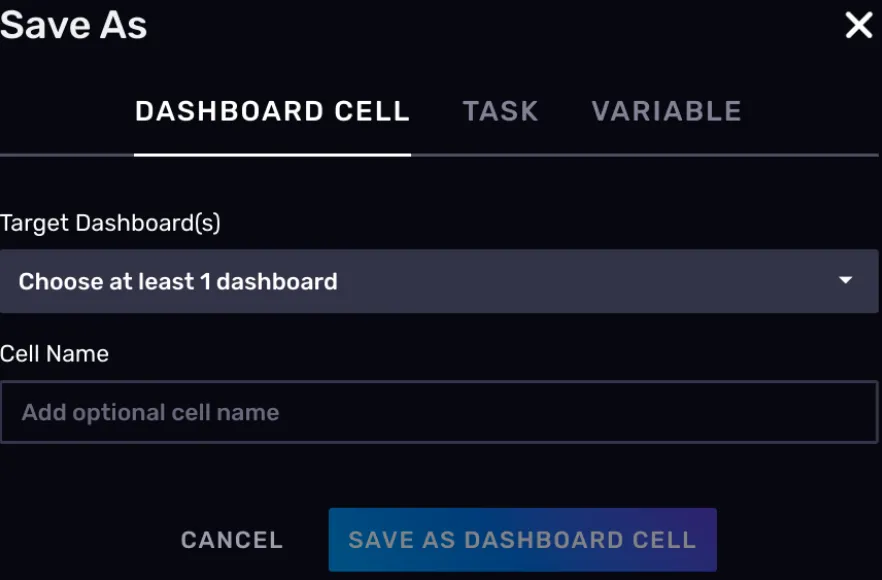
- 创建定时任务
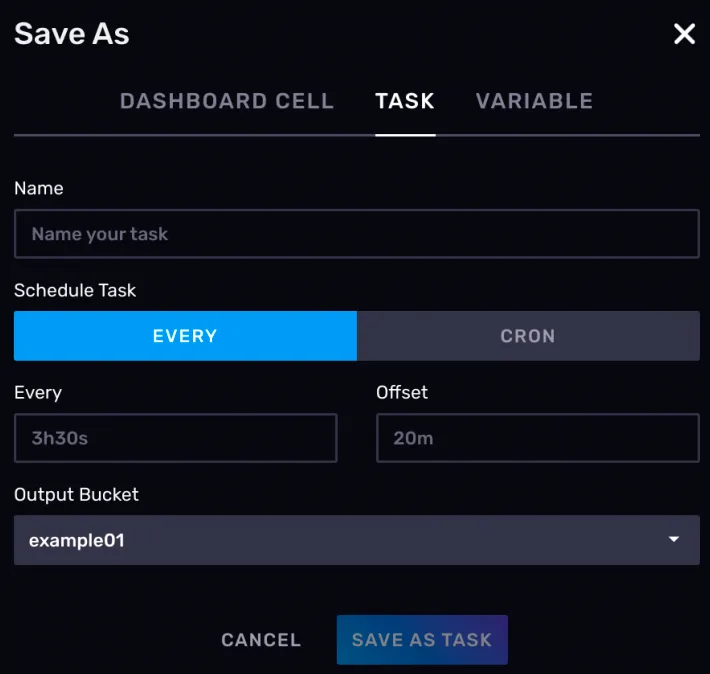
Data Explorer 中的查询逻辑可以保存为一个定时任务,也就是 TASK。这里提前说一下 InfluxDB 中的 TASK 是什么。TASK 其实是一个定时执行的 FLUX 语言写的脚本。因为FLUX 是一个脚本语言,所以它其实有一定的 IO 能力。可以使用 http 与外面的系统进行通信,还可以将计算完的数据回写给 InfluxDB。所以通常TASK 有两种使用场景。
- 数据检查与报警。对查询后的结果进行一下条件判断,如果不合规,就使用 http向外通知报警。
- 聚合操作。在 InfluxDB 里开窗完成聚合计算,计算后的数据再写回到 InfluxDB, 这样下游 BI(数据看板)可以直接去查询聚合后的数据了,而不是每次都把数据从InfluxDB 里拉出来重新计算。这样可以减少 IO,不过会增加 InfluxDB 的压力。生产环境下需要根据实际情况进行取舍。
- 定义全局变量
在 DataExplorer 里,你可以声明一些全局变量。全局变量的类型可以是 Map(键值对)、CSV 和 FLUX 脚本。这样,将来你可以直接引用这些变量,比如你的数据里有地区编码。你就可以将编码到地区名称的映射保存为一个全局Map,供以后每次查询时使用。
示例:在 Data Explorer 使用查询构造器进行查询和可视化
1)打开 Data Explorer
点击左侧的按钮,进入Data Explorer 页面。
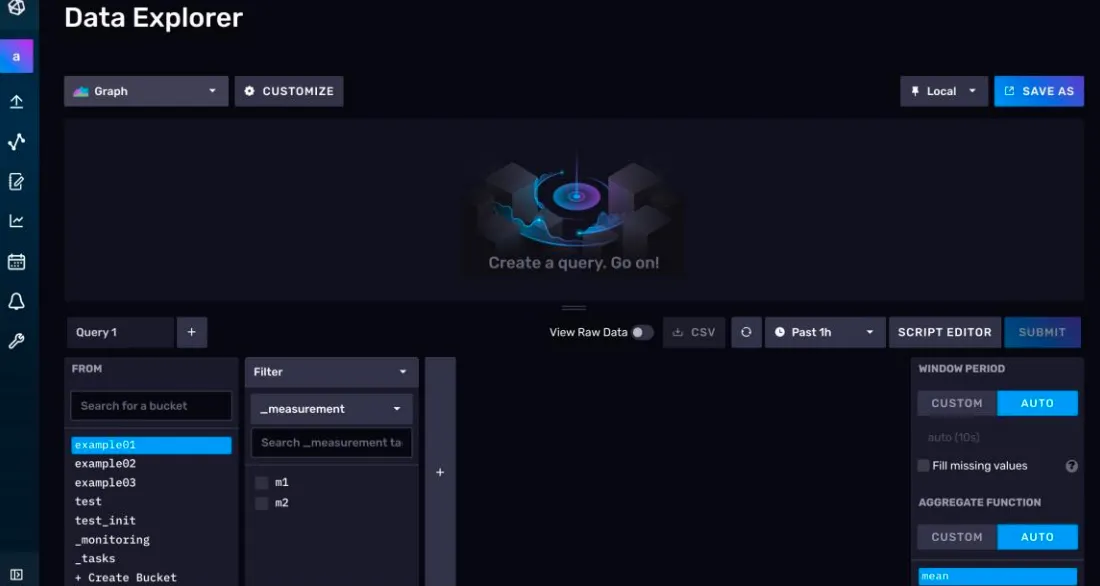
2)设置查询条件
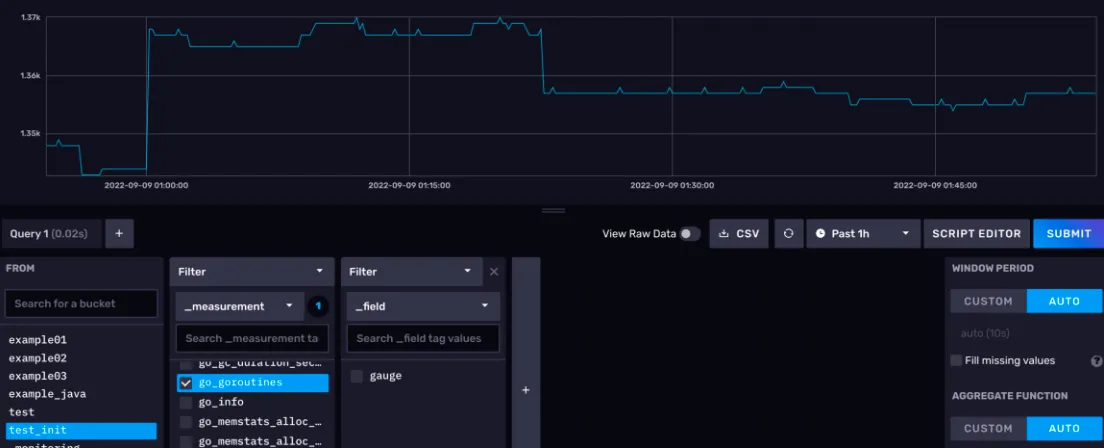
我们现在要查询的是 test_init 存储桶下的 go_goroutines 测量,这个测量反应的是我们InfluxDB 进程中的 goroutines(轻量级线程)数量。
首先,在左下角的查询构造器的 FROM 选项卡,选择 test_init 存储桶

接着会弹出一个 Filter 选项卡,默认情况下这里是选择_measurement,此处我们选择go_goroutines。
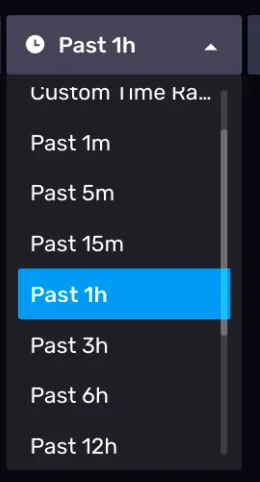
3)注意查询时间范围
右上角有一个带时钟符号的下拉菜单,这个菜单可以帮你纵向选择要查询数据的时间范围,通常默认是 1h。如下图所示:
4)注意右侧的窗口聚合选项
在查询构造器的最右边,有一个开窗聚合选项卡。使用查询构造器进行查询,就必须使用开窗聚合。默认情况下,DataExplorer 会根据你设置的查询时间范围,自动调整窗口大小,此处查询范围 1h 对应窗口大小 10s。
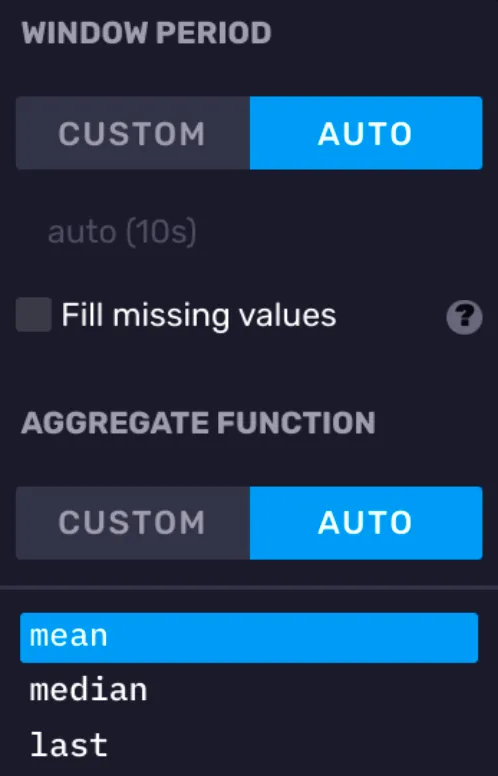
同时,聚合方式默认是平均值。
5)提交查询
点击右侧的 SUBMIT 按钮可以立刻提交查询。之后,数据展示区会出现相应的折线图。如下图所示:
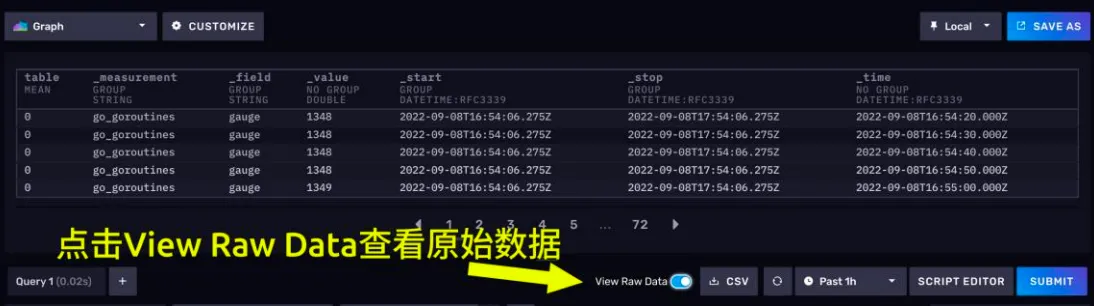
点击View Raw Data,可以看到原始数据。
6)查询原理
我们使用查询构造器进行查询,其实是 Web UI 根据我们指定的查询条件生成了一套FLUX 查询脚本。点击SCRIPT EDITOR 按钮,可以看到查询构造器生成的 FLUX 脚本。

7)可视化原理
其实默认情况下的可视化,是依据返回数据中的_value 来展示的,但是有些时候,你想查询的数据可能字段名不会被判别为_value。它会安静地躺在原始数据中。

Notebook
Notebook 是 InfluxDB2.x 推出的功能,交互上模仿了 Jupyter NoteBook。它可以用于开发、文档编写、运行代码和展示结果。
你可以将 InfluxDB 笔记本视为按照顺序处理数据的集合。每个步骤都由一个“单元格” 表示。一个单元格可以执行查询、可视化、处理或将数据写入存储桶等操作。Notebook 可以帮你完成下述操作:
-
执行 FLUX 代码、可视化数据和添加注释性的片段
-
创建报警或者计划任务
-
对数据进行降采样或者清洗
-
生成要和团队分享的 Runbooks
-
将数据回写到存储桶
Notebook 和 DataExplorer 相比,主要是交互风格上的不同。DataExplorer 倾向于一锤子买卖,而 Notebook 可以将数据展示拆分为一个又一个具体的步骤。另外,NoteBook 可以用来开发告警任务DataExplorer 则不能。
1)进入 Notebook 的导航界面
点击左侧的按钮,即可进入 Notebook 的导航页面。
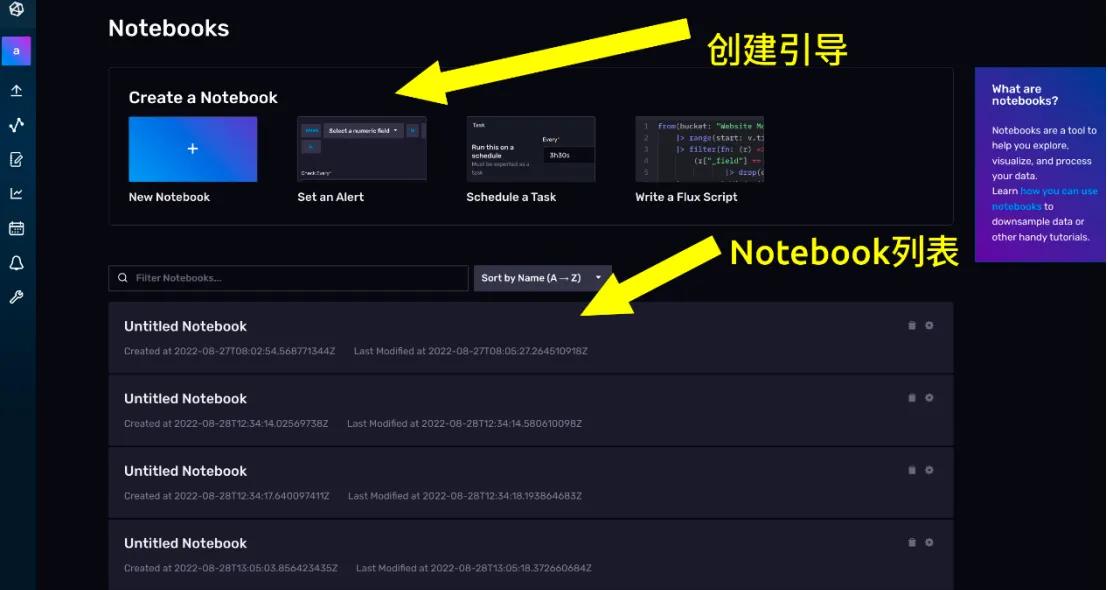
导航页面分两个部分:
-
上面是创建引导,除了创建一个空白的 Notebook,InfluxDB 还为你提供了 3 个模板。分别是 Set an Alert(设置一个报警)、Schedule a Task (调度一个任务)、write a Flux Script(写一个 Flux 脚本)。
-
下面是 Notebook 列表,过去你创建过的NoteBook 再这里都会展示出来。
卡片上还有这个 Notebook 对应的创建时间和修改时间。通过卡片你可以对一个 Notebook 重命名,还可以将它复制和删除。
2)创建一个空白的 notebook
想要继续后面的步骤,我们必须先创建一个 Notebook。
现在,你看到的就是 Notebook 的操作页面了。
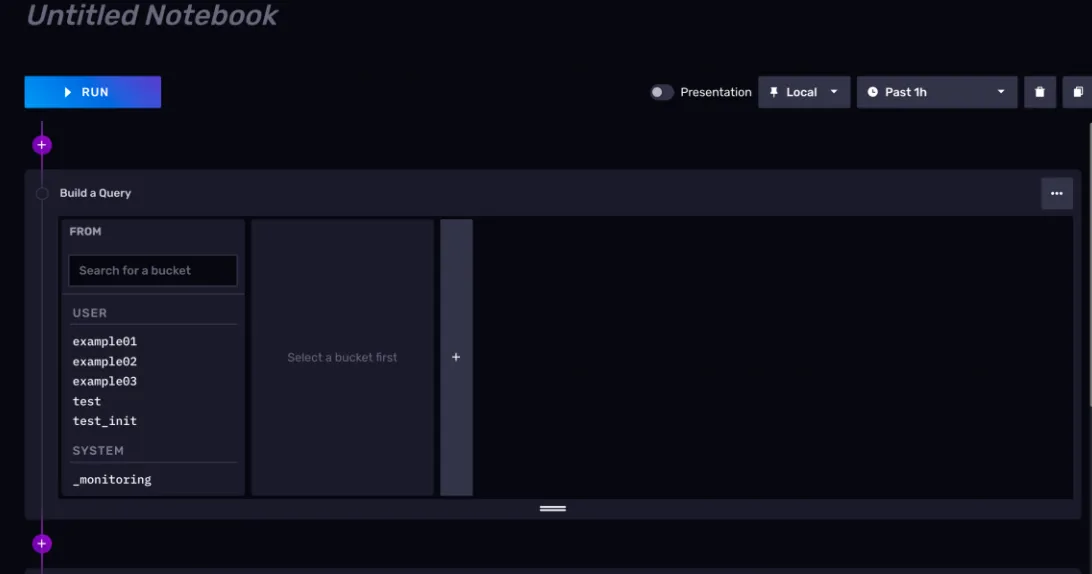
3)NoteBook 工作流
目前你看到的页面应当是如下图所示的样子。
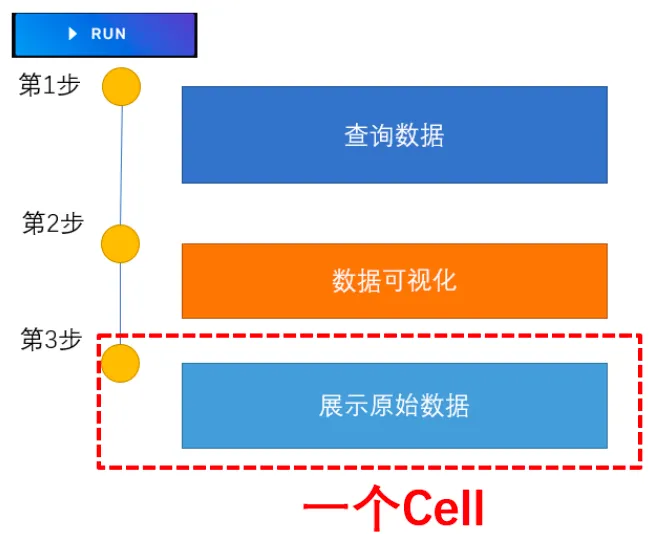
我们在页面中看到的一个又一个卡片,在 NoteBook 中叫做 Cell。一个 NoteBook 工作流就是多个 Cell 按照先后顺序组合起来的执行流程。这些 Cell 中间随时可以插入别的 Cell, 而且Cell 和Cell 还可以调换顺序。
按照Cell 功能,Cell 可以按照下面的方式分类。
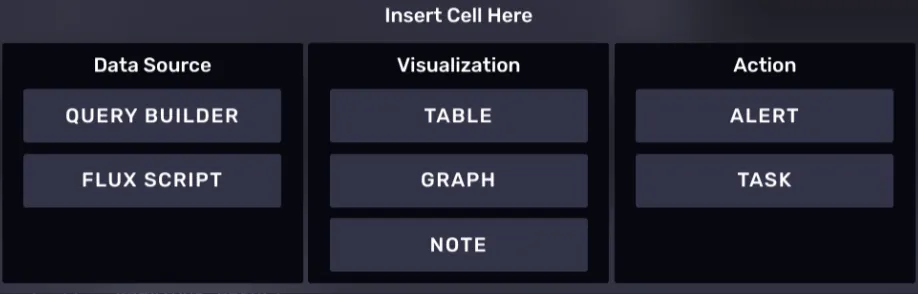
- 数据源相关的Cell
- 可视化相关的Cell
- 行为Cell
4)工作流范式
在 NoteBook 里编写工作流通常是有套路可循的。

通常一个 notebook 工作流以查询数据开始,后面的 Cell 跟上把数据展示出来,当数据需要进一步修改的时候,可以再加一个 FLUX 脚本 cell,notebook 为我们留了一个接口, 通过这种方式,后面的Flux cell 可以将前面的数据作为数据源进行查询。
最终,notebook 工作流可以以任务设置或者报警操作作为整个工作流的终点,当然这不是强制要求。
5)NoteBook 控件
在 notebook 上存在下述几种控件
-
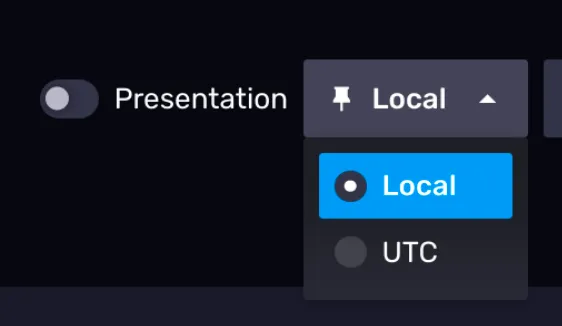
时区转换
右上角有一个 Local 按钮,通过这个按钮,你可以选择将日期时间显示为系统所设时区还是 UTC 时间。
-
仅显示可视化
点击 Presentation 按钮,可以选择是否仅显示数据展示的 cell。如果开启这个选项,那么查询构造器和FLUX 脚本的Cell 就会被折叠。
-
删除按钮
点击确定后,可以删除整个 notebook。
-
复制按钮
右上角的复制按钮可以立刻为当前NoteBook 创建一个副本。
-
运行按钮
RUN 按钮可以快速地执行Notebook 中的查询操作并重新渲染其中的可视化Cell。
示例:使用 NoteBook 查询和可视化数据
1)使用查询构造器进行查询
默认情况下,你创建的空白 NoteBook,自带 3 个 cell。
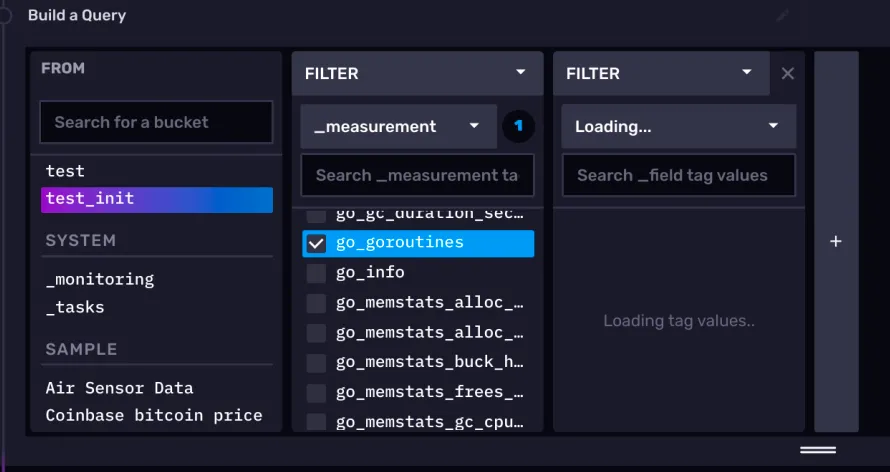
第一个 cell,默认是一个查询构造器,相对于 DataExplorer 来说,notebook 的查询构造器不同的地方在于它没有开窗聚合操作。
此处,同样还是查询 test_init 中的 go_goroutines 测量。
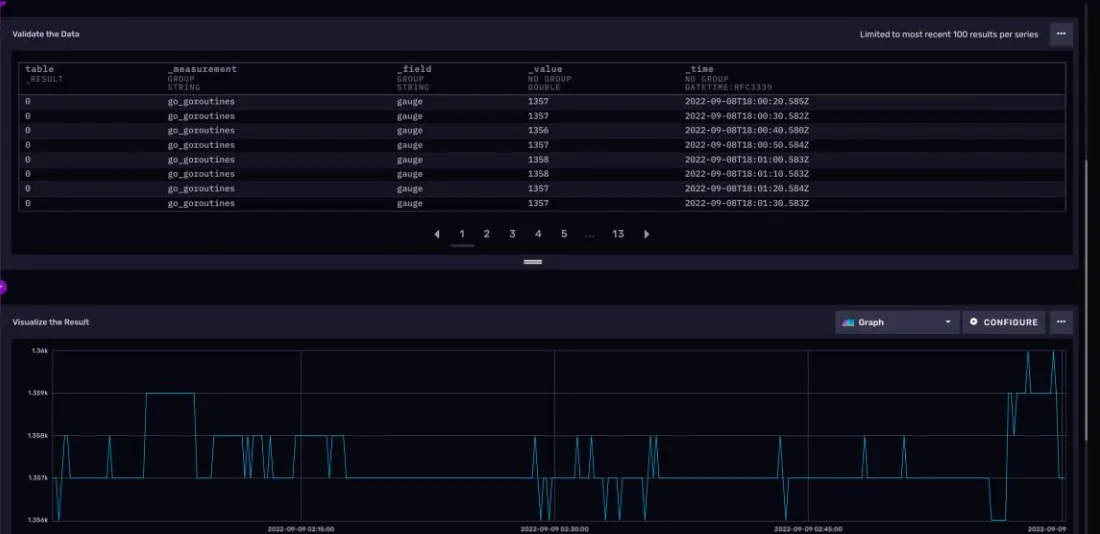
2)提交查询
点击RUN 按钮。可以看到下面的原始数据和折线图都出现了:
3)添加说明 cell
notebook 允许用户在工作流中加入说明性的 cell。我们选择在最前面加一个说明性 cell。
首先,点击左侧的紫色+号。
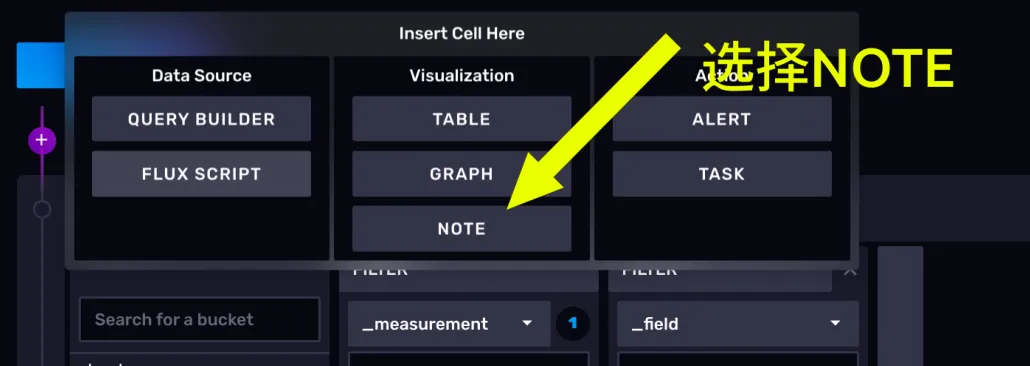
点击 NOTE 按钮。可以看到, 我们已经创建了一个说明 cell 。这里面还支持MarkDown 语法,

点击右上右上角的PREVIEW 按钮,markdown 就会被渲染展示。


本文作者:柳始恭
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!