
目录
在数字化浪潮席卷能源行业的今天,一座中型光伏电站每天产生着怎样的数据洪流?想象一下:数十万台逆变器如同数字神经末梢,每5分钟传递一次发电"心跳",一日便产生千万条数据记录。

当业务要求的复杂聚合查询需要跨越 320 张物理表进行分布式 JOIN —— 我们不禁要问:传统关系型数据库就算是分库分表,在处理光伏逆变器产生的海量时序数据时,是否已经触及了架构的天花板?
这正是无数新能源企业正在面对的真实困境。当发电数据从简单的记录存储升级为驱动决策的核心资产,传统数据库在时序数据处理的天然短板暴露无遗。区域发电效率对比、设备性能退化分析、发电量预测优化——这些关乎运营效率的关键分析,在现有架构下竟成了技术团队的噩梦。
但曙光已然显现。一种专为时序数据而生的新型数据库正在颠覆传统,它能否在百万级数据写入压力的同时,实现毫秒级的多维度复杂查询?当分库分表的桎梏被打破,我们是否终于可以任意穿梭于时间与维度之间,自由探索发电数据的每一个角落?本文将带你踏上一场存储架构的重构之旅,揭秘如何让海量光伏发电数据真正"发光发电"。
光伏发电大数据存储解决方案:从分库分表到时序数据库的实战演进
现有架构的痛点分析
当前系统采用分库分表方式存储光伏逆变器数据,已有9亿多条记录,且数据量持续快速增长。每个逆变器从早晨开始发电,每5分钟传输一条发电量信息,到傍晚停止传输。现有架构面临以下核心问题:
-
查询性能急剧下降:随着数据量增长,跨多个分表的查询性能显著降低
-
复杂条件过滤困难:按区域、逆变器型号、电站状态等多维度查询效率低下
-
时间范围查询效率低:查询日期区间发电量数据需要跨多个分表扫描
-
扩展性受限:传统数据库的分库分表需要人工干预,自动化程度低
光伏发电数据场景的深度分析
光伏发电数据是一种典型的时间序列数据,具有明显的时序特征:每个数据点都包含时间戳、数值和标签信息。在实际业务中,8万个逆变器从日出开始工作,每5分钟传输一条发电量数据,到傍晚停止传输。这种业务模式导致数据产生具有周期性、间歇性和季节性的特点。
根据行业数据,单个100MW风电场年数据量可达10TB+,而光伏电站同样面临数据量巨大的挑战。在我们的场景中,8万个逆变器每天产生的数据量相当可观:每5分钟8万条记录,按每天有效发电时间10小时计算,每天新增数据量达960万条。

同时光伏发电系统的数据查询需求复杂多样,主要包括:
-
时间区间查询:查询任意日期范围、时间区间的发电量汇总数据
-
多维度筛选:根据区域、逆变器型号、电站状态等条件进行筛选
-
实时监控:对当前发电状态进行实时监控和预警
-
历史数据分析:长期趋势分析、设备性能退化评估、发电效率优化
根据以上场景,最终我们选择了时序库 InfluxDB 作为核心时序数据存储解决方案。
InfluxDB 概念
InfluxDB 是一个专门处理时间序列数据的开源数据库。简单来说,就是专门存储带时间戳数据的数据库。比如股票价格变化、服务器CPU使用率、传感器温度读数等等。
想象一下,你有一个温度传感器,每分钟记录一次温度。这些数据按时间顺序排列,就是典型的时间序列数据。InfluxDB就是为了高效处理这类数据而生的。
数据结构组成
InfluxDB 的数据结构包含几个核心部分:
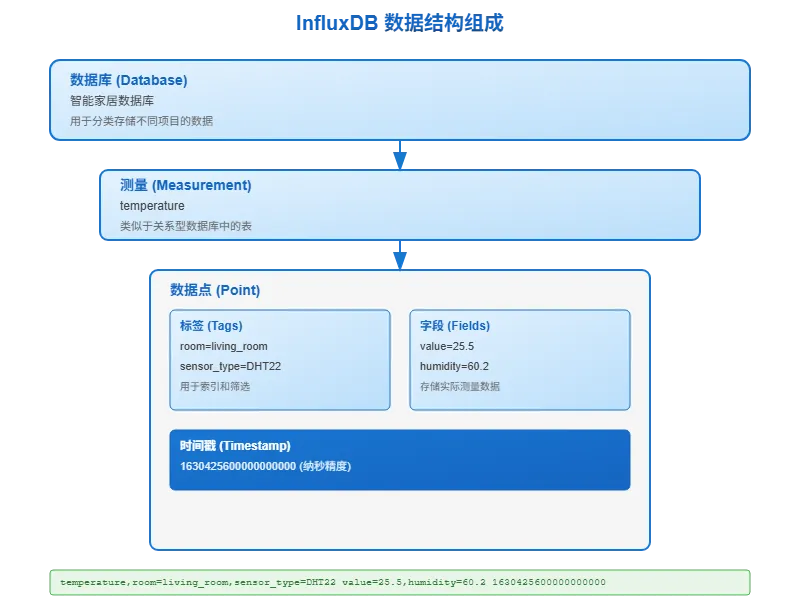
数据库(Database)
就像MySQL里的数据库概念一样,用来分类存储不同项目的数据。比如你可以建一个"智能家居"数据库,专门存放家里各种传感器的数据。
测量(Measurement)
这个概念类似于关系型数据库中的表。每个测量代表一类数据,比如"温度测量"、“湿度测量”、"网络流量测量"等。
标签(Tags)
标签是用来给数据打标记的,方便后续查询和筛选。比如温度数据,你可以用标签标记是哪个房间的、哪种传感器类型的。标签的值只能是字符串。
字段(Fields)
字段存储真正的数值数据。比如温度值25.5度、湿度60%等。字段可以存储各种数据类型:整数、小数、字符串、布尔值。
时间戳(Timestamp)
每条数据都必须有时间戳,精确到纳秒级别。这是InfluxDB的核心,所有数据都按时间排序。
举个例子,一条完整的数据可能长这样:
texttemperature,room=living_room,sensor_type=DHT22 value=25.5,humidity=60.2 1630425600000000000
这里:
temperature是测量名room=living_room,sensor_type=DHT22是标签value=25.5,humidity=60.2是字段- 最后那串数字是时间戳
核心概念详解
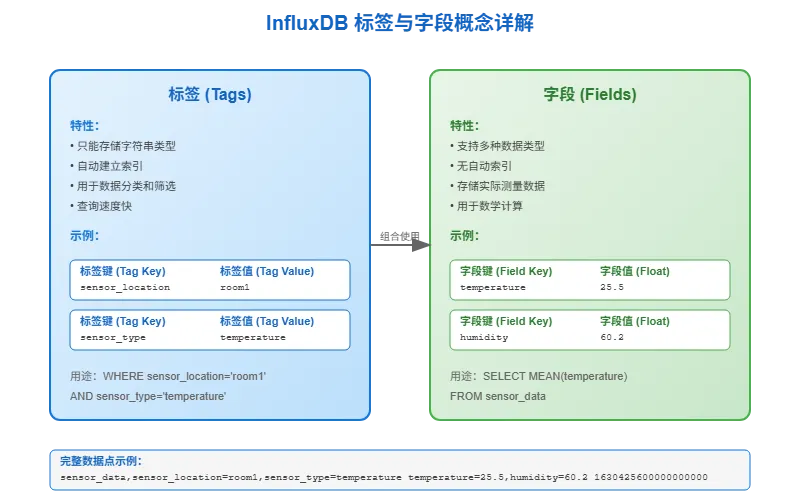
标签键和标签值
标签键(Tag Keys)
标签的名字,比如 sensor_location、sensor_type。这些都是字符串,主要用来分类和索引数据。
标签值(Tag Values)
标签对应的具体值,比如 room1、temperature。也必须是字符串。
标签的组合帮你快速找到想要的数据。比如你想查"客厅的温度传感器数据",就可以通过 sensor_location=living_room 和 sensor_type=temperature 这两个标签组合来查询。
textmeasurement,sensor_location=room1,sensor_type=temperature value=25.5 1630425600000000000
在这个例子中:
sensor_location和sensor_type是标签键room1和temperature是对应的标签值
字段键
字段键(Field Keys)
字段的名字,比如 temperature、humidity、pressure。字段键对应的值可以是各种数据类型,不像标签只能是字符串。
字段存储的是你真正关心的测量数据。比如:
textmeasurement,sensor_location=room1,sensor_type=temperature temperature=25.5,humidity=60.2 1630425600000000000
这里 temperature 和 humidity 就是字段键,25.5 和 60.2 是对应的数值。
序列(Series)
序列(Series)
序列是一个逻辑概念,指的是具有相同测量名和标签组合的所有数据点。
比如说,所有来自"客厅温度传感器"的数据点就构成一个序列。即使时间不同、温度值不同,但只要是同一个传感器(相同的标签组合),就属于同一个序列。
假设你有这样的数据:
textsensor_data,sensor_location=room1,sensor_type=temperature temperature=25.5 1630425600000000000 sensor_data,sensor_location=room1,sensor_type=temperature temperature=26.0 1630425660000000000 sensor_data,sensor_location=room1,sensor_type=temperature temperature=25.8 1630425720000000000
这三条数据就属于同一个序列,因为它们有相同的测量名(sensor_data)和相同的标签组合(sensor_location=room1,sensor_type=temperature)。

关键区别总结
数据类型差异
标签(Tags)只能存储字符串,而字段(Fields)可以存储多种数据类型:
- 整数:
count=100 - 浮点数:
temperature=25.5 - 字符串:
status="online" - 布尔值:
is_active=true
功能用途不同
标签的作用
- 数据分类和筛选
- 建立索引,加快查询速度
- 类似于数据库的WHERE条件
字段的作用
- 存储实际的测量数据
- 用于数学计算和聚合操作
- 这是你真正要分析的数据
序列的作用
- 数据组织和管理
- 查询优化
- 理解数据的逻辑分组
索引特性
InfluxDB 会自动为所有标签建立索引,所以按标签查询很快。但字段没有自动索引,如果要按字段值查询,可能会比较慢。

这就是为什么要合理设计标签和字段:
- 经常用来筛选的属性设为标签
- 需要计算分析的数值设为字段
比如传感器数据:
- 传感器位置、类型 → 设为标签(经常用来筛选)
- 温度值、湿度值 → 设为字段(需要计算平均值、最大值等)
掌握了这些基础概念,你就能更好地设计InfluxDB的数据结构,让查询更快、存储更合理。
实战:InfluxDB 数据模型设计
数据点结构设计
java// 逆变器发电量数据点
public class InverterDataPoint {
private String measurement = "power_generation";
// Tags - 用于过滤和分组
private String inverterId; // 逆变器ID
private String region; // 区域
private String modelType; // 型号
private String stationStatus; // 电站状态
private String province; // 省份
private String city; // 城市
// Fields - 实际测量值
private Double powerOutput; // 发电功率(kW)
private Double dailyEnergy; // 日发电量(kWh)
private Double temperature; // 设备温度(℃)
private Double voltage; // 电压(V)
private Integer statusCode; // 状态码
// Timestamp
private Long timestamp; // 数据时间戳
}
数据写入优化
java@Component
public class InfluxDBWriter {
@Autowired
private InfluxDB influxDB;
private static final int BATCH_SIZE = 5000;
private List<Point> batchPoints = new ArrayList<>();
/**
* 批量写入逆变器数据
*/
@Async
public void writeInverterData(List<InverterData> dataList) {
List<Point> points = dataList.stream()
.map(this::convertToPoint)
.collect(Collectors.toList());
// 批量写入优化
if (batchPoints.size() + points.size() >= BATCH_SIZE) {
flushBatch();
}
batchPoints.addAll(points);
}
private Point convertToPoint(InverterData data) {
return Point.measurement("power_generation")
.time(data.getTimestamp(), TimeUnit.MILLISECONDS)
.tag("inverter_id", data.getInverterId())
.tag("region", data.getRegion())
.tag("model_type", data.getModelType())
.tag("station_status", data.getStationStatus())
.tag("province", data.getProvince())
.tag("city", data.getCity())
.addField("power_output", data.getPowerOutput())
.addField("daily_energy", data.getDailyEnergy())
.addField("temperature", data.getTemperature())
.addField("voltage", data.getVoltage())
.addField("status_code", data.getStatusCode())
.build();
}
@Scheduled(fixedRate = 5000) // 5秒刷写一次
public void flushBatch() {
if (!batchPoints.isEmpty()) {
influxDB.write(batchPoints);
batchPoints.clear();
}
}
}
复杂查询场景实战
时间区间发电量汇总
java/**
* 查询指定时间区间内的总发电量
*/
public PowerSummary queryPowerSummary(String startTime, String endTime,
List<String> regions, String modelType) {
String fluxQuery = String.format(
"from(bucket: \"%s\")\n" +
" |> range(start: %s, stop: %s)\n" +
" |> filter(fn: (r) => r._measurement == \"power_generation\")\n" +
" |> filter(fn: (r) => r._field == \"power_output\")\n" +
" |> filter(fn: (r) => r.region =~ /%s/)\n" +
" |> filter(fn: (r) => r.model_type == \"%s\")\n" +
" |> aggregateWindow(every: 1h, fn: mean)\n" +
" |> sum()",
BUCKET_NAME, startTime, endTime,
String.join("|", regions), modelType
);
return executeFluxQuery(fluxQuery);
}
多维度条件过滤查询
java/**
* 复杂条件查询:区域、型号、状态多维度组合
*/
public List<InverterStats> queryInverterStats(PowerQueryDTO queryDTO) {
StringBuilder fluxBuilder = new StringBuilder();
fluxBuilder.append(String.format(
"from(bucket: \"%s\")\n" +
" |> range(start: %s, stop: %s)\n" +
" |> filter(fn: (r) => r._measurement == \"power_generation\")\n",
BUCKET_NAME, queryDTO.getStartTime(), queryDTO.getEndTime()
));
// 动态添加过滤条件
if (CollectionUtils.isNotEmpty(queryDTO.getRegions())) {
String regionFilter = queryDTO.getRegions().stream()
.map(region -> "/" + region + "/")
.collect(Collectors.joining("|"));
fluxBuilder.append(String.format(
" |> filter(fn: (r) => r.region =~ %s)\n", regionFilter
));
}
if (StringUtils.isNotEmpty(queryDTO.getModelType())) {
fluxBuilder.append(String.format(
" |> filter(fn: (r) => r.model_type == \"%s\")\n",
queryDTO.getModelType()
));
}
if (StringUtils.isNotEmpty(queryDTO.getStationStatus())) {
fluxBuilder.append(String.format(
" |> filter(fn: (r) => r.station_status == \"%s\")\n",
queryDTO.getStationStatus()
));
}
fluxBuilder.append(
" |> group(columns: [\"inverter_id\"])\n" +
" |> mean()\n" +
" |> sort(desc: true)\n" +
" |> limit(n: 1000)"
);
return executeComplexQuery(fluxBuilder.toString());
}
实时聚合与降采样
java/**
* 创建连续查询进行实时数据聚合
*/
public void createContinuousQueries() {
// 按小时聚合
String hourlyAggregation =
"CREATE CONTINUOUS QUERY cq_power_hourly ON photovoltaic \n" +
"BEGIN \n" +
" SELECT MEAN(power_output) as mean_power, \n" +
" SUM(daily_energy) as total_energy \n" +
" INTO photovoltaic.autogen.:MEASUREMENT \n" +
" FROM power_generation \n" +
" GROUP BY time(1h), region, model_type \n" +
"END";
// 按天聚合
String dailyAggregation =
"CREATE CONTINUOUS QUERY cq_power_daily ON photovoltaic \n" +
"BEGIN \n" +
" SELECT MEAN(mean_power) as daily_mean_power, \n" +
" SUM(total_energy) as daily_total_energy \n" +
" INTO photovoltaic.one_year.daily_power \n" +
" FROM photovoltaic.autogen.power_generation \n" +
" GROUP BY time(1d), region, model_type \n" +
"END";
influxDB.query(new Query(hourlyAggregation));
influxDB.query(new Query(dailyAggregation));
}
迁移方案与实施路径
平滑迁移策略
从分库分表方案迁移到InfluxDB需要谨慎规划,确保业务连续性:
分阶段迁移方案:
-
并行运行阶段(1-2周):新老系统同时运行,数据双写,验证数据一致性
-
查询迁移阶段(2-3周):逐步将查询业务迁移到新系统,按业务重要性从低到高
-
历史数据迁移阶段(3-4周):逐步迁移历史数据,按时间从近到远
-
老系统下线阶段(1周):完全切换到新系统,老系统只读备用
数据双写实现:
java// 双写管理器
@Component
public class DualWriteManager {
@Value("${dual.write.enabled:true}")
private boolean dualWriteEnabled;
public void writeGenerationData(PowerGenerationData data) {
// 写入InfluxDB
writeToInfluxDB(data);
// 双写期间同时写入MySQL
if (dualWriteEnabled) {
writeToMySQL(data);
}
}
public void switchToSingleWrite() {
this.dualWriteEnabled = false;
// 切换后仅写入InfluxDB
}
}
数据一致性保障
迁移过程中必须确保数据一致性,一致性检查方案:
java// 数据一致性校验
@Service
public class DataConsistencyChecker {
public ConsistencyResult checkConsistency(String startTime, String endTime) {
// 从InfluxDB查询统计
PowerStatistic influxStat = queryFromInfluxDB(startTime, endTime);
// 从MySQL查询统计
PowerStatistic mysqlStat = queryFromMySQL(startTime, endTime);
// 对比结果
return compareStatistics(influxStat, mysqlStat);
}
private ConsistencyResult compareStatistics(PowerStatistic s1, PowerStatistic s2) {
double diff = Math.abs(s1.getTotalGeneration() - s2.getTotalGeneration());
double tolerance = s1.getTotalGeneration() * 0.01; // 1%容差
if (diff <= tolerance) {
return ConsistencyResult.ok();
} else {
return ConsistencyResult.error("数据不一致,差异: " + diff);
}
}
}
InfluxDB 带来的价值
通过迁移到InfluxDB,我们实现了:
性能优化
-
时间范围查询从分钟级降至秒级
-
复杂条件查询性能提升5-10倍
-
写入吞吐量满足逆变器增量并发需求
成本优化
-
存储压缩比达到1:8,存储成本降低60%
-
自动数据分层,冷数据存储成本进一步降低
-
减少运维复杂度,降低人力成本
业务价值
-
支持实时监控和大屏展示
-
赋能精准发电预测和故障预警
-
为电站运营决策提供数据支撑
InfluxDB 作为专业的时序数据库,在光伏发电监控场景中展现出了显著优势,为海量时序数据的存储和分析提供了完美的解决方案。
技术选型的关键:认清数据本质——光伏逆变器数据是典型的时间序列数据,选择专业的时序数据库而非通用的关系型数据库,是解决性能瓶颈的根本之道。


本文作者:柳始恭
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!